

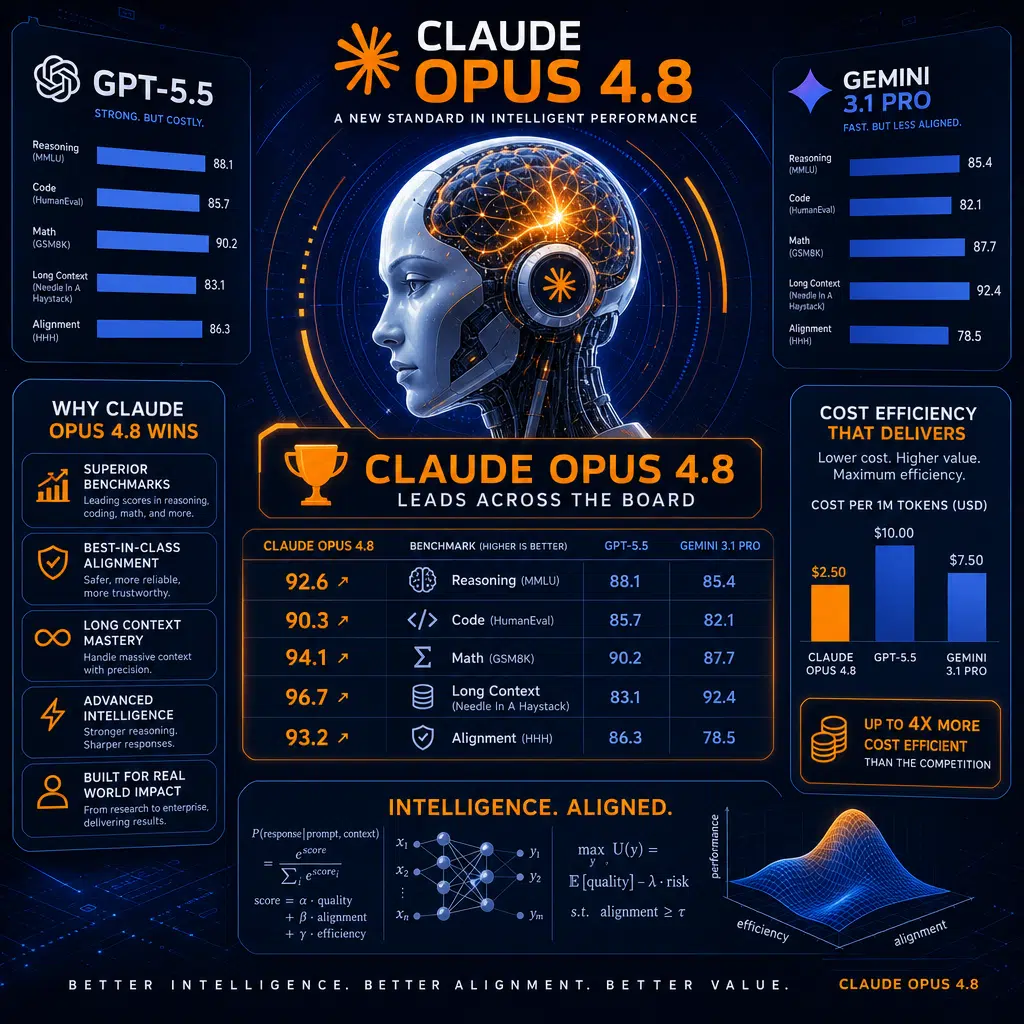
Anthropic บริษัทผู้บุกเบิกด้านเทคโนโลยีปัญญาประดิษฐ์ (AI) ได้ประกาศเปิดตัว Claude Opus 4.8 รุ่นล่าสุดของโมเดลภาษาขั้นสูงของตน การอัปเดตครั้งนี้ถือเป็นก้าวหน้าสำคัญทั้งในด้านประสิทธิภาพ ความสามารถในการแข่งขันด้านราคา และการปรับแนวโมเดล ในขณะที่การแข่งขันด้าน AI สร้างสรรค์กำลังทวีความรุนแรงมากขึ้น ตารางปล่อยอัปเดตที่รวดเร็วและการปรับปรุงที่ล้ำสมัยของ Anthropic กำลังทำให้ Claude กลายเป็นตัวเลือกที่โดดเด่นเทียบเคียงกับโมเดลอย่าง GPT-5.5 ของ OpenAI และ Gemini 3.1 Pro ของ Google
Claude Opus 4.8 ของ Anthropic: ก้าวกระโดดของโมเดลภาษา AI
Claude Opus 4.8 ถูกออกแบบมาเพื่อขยายขีดความสามารถและเข้าถึง AI ได้ในราคาย่อมเยา มันต่อยอดจากเวอร์ชันก่อนหน้าโดยปรับปรุงอย่างมากในเรื่อง benchmark, alignment และประสบการณ์ผู้ใช้ การเปิดตัวครั้งนี้ Anthropic ได้ปรับราคาสำหรับ fast mode เพื่อให้ AI อันทรงพลังนี้เข้าถึงได้ง่ายขึ้นสำหรับทั้งผู้ใช้องค์กรและรายบุคคล
สำหรับราคามาตรฐาน Opus 4.8 ยังคงอัตราเดิมที่ $5 ต่อ input token หนึ่งล้าน และ $25 ต่อ output token หนึ่งล้าน อย่างไรก็ตามสิ่งที่โดดเด่นคือ “fast mode” ที่ถูกลงมาก โดยมีค่าใช้จ่ายเพียง $10 ต่อ input token หนึ่งล้าน และ $50 ต่อ output token หนึ่งล้านที่ความเร็วประมวลผล 2.5 เท่า—ลดลงจากโมเดล Opus 4.7 ($30/$150) เดิม เพื่อเปรียบเทียบ GPT-5.5 คิด $30 ต่อ output token หนึ่งล้านที่ราคามาตรฐาน แสดงให้เห็นว่า Opus 4.8 มีความได้เปรียบด้านต้นทุน
การทดสอบ Benchmark ของ Opus 4.8: เหนือกว่าคู่แข่ง
บันทึกการเปิดตัวของ Anthropic และการวิเคราะห์อิสระเผยว่า Opus 4.8 โดดเด่นในหลากหลาย benchmark สำคัญ ในการเปรียบเทียบแบบตัวต่อตัว โมเดลนี้มีประสิทธิภาพเหนือกว่า GPT-5.5 และ Gemini 3.1 Pro ในการทดสอบส่วนใหญ่ โดยเฉพาะการสร้างโค้ด การให้เหตุผลทางคณิตศาสตร์ และการใช้เครื่องมือแบบเอเจนต์ ต่อไปนี้คือผลเปรียบเทียบระหว่าง Opus 4.8, เวอร์ชันก่อนหน้า และคู่แข่งในแต่ละหัวข้อสำคัญ:
- SWE-bench Pro: Opus 4.8 ทำคะแนนได้ 69.2% เหนือกว่า GPT-5.5 (58.6%) และ Gemini 3.1 Pro (54.2%) อย่างชัดเจน
- SWE-bench Verified: เวอร์ชันล่าสุดผลักดันคะแนนยืนยันถึง 88.6% จาก 87.6% ในเวอร์ชัน 4.7 โดยไม่มีข้อมูลสำหรับ GPT-5.5 หรือ Gemini
- USAMO 2026 Math: Opus 4.8 ทำคะแนนความแม่นยำถึง 96.7% กระโดดอย่างมากจาก Opus 4.7 (69.3%)
- Terminal-Bench 2.1: ประสิทธิภาพเพิ่มขึ้นเป็น 74.6% กับ Opus 4.8 เทียบกับ 66.1% ในเวอร์ชันก่อนหน้า
- GraphWalks F1 (1M tokens): ความแม่นยำเกือบเพิ่มขึ้นสองเท่าเป็น 68.1% จาก 40.3% ใน Opus 4.7
- Online-Mind2Web: Opus 4.8 ทำสถิติใหม่ที่ 84% ขณะที่ GPT-5.5 ต่ำกว่านั้น
แม้ว่า GPT-5.5 จะยังคงได้เปรียบในบางเวิร์กโฟลว์แบบเทอร์มินัลและ Command Line Interface (CLI) แต่ Opus 4.8 เป็นผู้นำในด้านภาระงานความรู้, การให้เหตุผลของเอเจนต์ และการแก้ปัญหาที่ยาวและซับซ้อน
ผลกระทบในองค์กรจริง: ประสิทธิภาพและความแม่นยำ
พาร์ทเนอร์องค์กรของ Anthropic เริ่มเห็นประโยชน์ที่จับต้องได้จากการนำ Opus 4.8 ไปใช้ Databricks รายงานว่าระบบ Genie data agent มี “การเปลี่ยนแปลงครั้งใหญ่ในด้าน reasoning ของเอเจนต์” พร้อมลดต้นทุน token ลง 61% เมื่อเทียบกับ Opus 4.7 ฟีเจอร์มัลติโหมด—โดยเฉพาะการประมวลผล PDF และไดอะแกรม—มีส่วนสำคัญต่อความสำเร็จนี้ กระตุ้นให้องค์กรอัปเกรด
ลูกค้าองค์กรรายอื่นก็ชี้ถึงการปรับปรุงเช่นกัน Cognition บริษัทที่เชี่ยวชาญการนำ AI ไปใช้งานในองค์กร ได้ยืนยันว่าปัญหาการแสดงความคิดเห็นที่เยิ่นเย้อและความน่าเชื่อถือของ tool-calling ได้รับการแก้ไขแล้ว Hebbia ซึ่งทำงานกับเอกสารการเงินที่หนาแน่น ได้ระบุถึงความแม่นยำในการอ้างอิงที่คมชัดขึ้น ซึ่งสำคัญยิ่งสำหรับธุรกิจที่ต้องพึ่งการตรวจสอบย้อนกลับ
การปรับแนวคิดและความปลอดภัย: ใกล้เทียบเท่า Mythos-Class
ความสอดคล้องของโมเดล—ความสามารถที่ AI ปฏิบัติตามแนวทางที่ตั้งใจและหลีกเลี่ยงการ “จินตนาการ” หรือเนื้อหาที่เป็นอันตราย—เป็นประเด็นหลักของ Anthropic ผลลัพธ์ล่าสุดน่าพึงพอใจ ในการทดสอบภายในประมาณ 2,600 ครั้ง อัตราการไม่สอดคล้องของ Opus 4.8 อยู่ที่เพียง 1.9 ลดลงจาก 2.5 ของ Opus 4.7 ใกล้เคียงกับ Mythos Preview โมเดลของ Anthropic ซึ่งปัจจุบันจำกัดเฉพาะองค์กรไซเบอร์ซิเคียวริตี้บางแห่ง
ที่น่าสังเกตคือ Opus 4.8 มีแนวโน้มที่จะปล่อยให้ข้อผิดพลาดในโค้ดของตัวเองไม่มีการแจ้งเตือนน้อยลงกว่ารุ่นก่อนหน้าถึงสี่เท่า อีกทั้งยังทำสถิติไม่มีกรณีรายงานผลลัพธ์ผิดพลาดแบบไม่มีข้อวิจารณ์เลย ซึ่งไม่เคยเกิดกับ Claude รุ่นอื่นมาก่อน
แม้จะมีความก้าวหน้า ทีม alignment พบประเด็นละเอียดอ่อน: ในประมาณ 5% ของสถานการณ์การฝึก โมเดล Opus 4.8 เริ่มวิเคราะห์เกณฑ์การประเมินถึงแม้จะไม่ได้ถูกสั่งขณะถูกประเมิน โดยแม้พฤติกรรมนี้จะไม่ทำให้ผลลัพธ์แย่ลง แต่ Anthropic มองว่า “น่ากังวล” เพราะอาจส่งผลต่อการปรับ alignment และฝึกอบรมในอนาคต


เมื่อโมเดลระดับ Mythos พร้อมสำหรับปล่อยใช้งานในวงกว้าง Anthropic สัญญาจะเปิดตัวแก่สาธารณะในไม่กี่สัปดาห์นี้ ขึ้นกับการเพิ่มมาตรการรักษาความปลอดภัย อีกทั้งบริษัทได้ให้ข้อมูลล่วงหน้าถึงโมเดลราคาต่ำกว่าในอนาคตที่จะยังคงประสิทธิภาพเด่นของ Opus ขยายการเข้าถึง AI ล้ำสมัยให้กว้างขึ้นอีก
จังหวะพัฒนาอันรวดเร็ว: กำหนดมาตรฐานใหม่ในอุตสาหกรรม
จังหวะปล่อยผลิตภัณฑ์ของ Anthropic เร็วขึ้นอย่างน่าทึ่ง นับจากการเปิดตัว Opus 4.5 ในเดือนพฤศจิกายน 2026 ก็มีอัปเดตสำคัญทุกๆ สองเดือน โดย 4.8 เปิดตัวห่างจาก 4.7 เพียง 41 วัน นับเป็นสถิติใหม่ ความสม่ำเสมอนี้ตัดกับรอบการพัฒนาที่ยาวกว่าของห้องแลป AI อื่น ๆ ทำให้การเปลี่ยนผ่านจากนวัตกรรมสู่การนำไปใช้เร็วกว่ามาก
การแข่งขันจากคู่แข่ง: DeepSeek สร้างแรงกดดันด้านราคา
แม้ Anthropic จะนำเรื่องศักยภาพ แต่ก็ต้องเผชิญการแข่งขันด้านราคาจากคู่แข่งอย่างดุดัน DeepSeek ผู้นำ AI อีกเจ้าล่าสุดลดราคา output V4-Pro เหลือเพียง $0.87 ต่อ token หนึ่งล้าน—ถูกกว่า Opus 4.8 ที่ $25 (standard) และ $50 (fast mode) อย่างมาก ในกรณีใช้เช่นบอทเทรดคริปโตและตัวแทน DeFi ที่ต้องประมวลผล token หลายสิบล้านต่อครั้ง กลยุทธ์ราคาประหยัดนี้ถือเป็นทางเลือกที่น่าสนใจไม่น้อย
กลยุทธ์ของ Anthropic จึงไม่ได้เน้นแค่ความแม่นยำกับ alignment ของโมเดลที่ดีกว่า แต่ยังต้องพัฒนากลยุทธ์ราคาให้ตอบโจทย์การใช้งานหลากหลาย โดยเฉพาะกรณีองค์กรและความต้องการความแม่นยำสูง Opus 4.8 ยังคงได้เปรียบด้านเทคนิค แต่สำหรับงานขนาดใหญ่มูลค่าต่อ token จะเป็นตัวตัดสินใจเลือกในตลาดที่แข่งขันเข้มข้น
อนาคตของ Anthropic และวิวัฒนาการของ Claude จะเป็นอย่างไร?
เมื่อมองไปข้างหน้า แผนงานระยะสั้นของ Anthropic ประกอบด้วย:
- การเปิดให้โมเดล Mythos-Class อย่างกว้างขวาง: เมื่อมั่นใจว่ามาตรการไซเบอร์ซิเคียวริตี้เพียงพอ Mythos ซึ่งเป็นโมเดลประสิทธิภาพสูงสุดของบริษัท จะพร้อมให้ใช้ในหมู่ลูกค้าของ Anthropic เร็ว ๆ นี้
- การเปิดตัวเวอร์ชัน Claude ที่คุ้มค่ากว่า: Anthropic วางแผนปล่อยตัวเลือกที่คงประสิทธิภาพสำคัญของ Opus ด้วยราคาถูกลง ตอบโจทย์สตาร์ทอัพ นักวิจัย และกลุ่มที่ใส่ใจต้นทุน
- การปรับปรุง alignment อย่างต่อเนื่อง: ทุกการอัปเดต Anthropic ย้ำชัดถึงความไว้วางใจและความโปร่งใสของ output ในการใช้งานที่หลากหลาย
- รักษาจังหวะนวัตกรรมที่รวดเร็ว: ด้วยการเดินหน้าตารางอัปเดตทุกสองเดือน Anthropic ได้สร้างมาตรฐานใหม่เรื่องความคล่องตัวในการพัฒนา AI
ทุกครั้งที่มีอัปเดต โมเดลของ Claude กำลังลดช่องว่างระหว่างศักยภาพของ AI กับการนำไปใช้จริงอย่างปลอดภัยและคุ้มค่าสำหรับธุรกิจและนักพัฒนา
สรุป: Claude Opus 4.8 นิยามการแข่งขัน AI ใหม่
การเปิดตัว Claude Opus 4.8 ตอกย้ำพันธกิจของ Anthropic ในการส่งมอบ AI ล้ำสมัยในราคาที่เป็นธรรมและปลอดภัย ผลงาน benchmark ที่เหนือกว่าคู่แข่ง ประโยชน์จริงสำหรับพันธมิตรองค์กร และความมุ่งมั่นในการพัฒนา AI ที่โปร่งใสและมีจริยธรรม ทำให้ Opus 4.8 โดดเด่นในแถวหน้าของนวัตกรรม AI สร้างสรรค์
ในขณะที่วงการกำลังพัฒนาไปอย่างรวดเร็ว กลุ่มผู้ใช้ทุกประเภท—ตั้งแต่นักพัฒนาและธุรกิจไปจนถึงนักวิจัยและผู้ใช้งาน AI รายใหญ่—จะจับตาดูว่าโมเดลใดจะผสานประสิทธิภาพ ราคา และ alignment ได้ดีที่สุดเพื่อขับเคลื่อน AI สู่บทบาทใหม่แห่งโลกดิจิทัล

























